YOLOv4 — the most accurate real-time neural network on MS COCO dataset.
Darket YOLOv4 is faster and more accurate than real-time neural networks Google TensorFlow EfficientDet and FaceBook Pytorch/Detectron RetinaNet/MaskRCNN on Microsoft COCO dataset.
Article: https://arxiv.org/abs/2004.10934
Code: https://github.com/AlexeyAB/darknet
Yolov v4 tiny discussion 1770 FPS: https://www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4/
Discussion: https://www.reddit.com/r/MachineLearning/comments/gydxzd/p_yolov4_the_most_accurate_realtime_neural/

We demonstrate the nuances of comparing and using neural networks to detect objects. Our goal was to develop an algorithm for use in real production, and not just for moving science forward. Accuracy of YOLOv4 (608x608) — 43.5% AP / 65.7% AP50 Microsoft-COCO-testdev.
62 FPS — YOLOv4 (608x608 batch=1) on Tesla V100 — by using Darknet-framework
400 FPS — YOLOv4 (320x320 batch=4) on RTX 2080 Ti — by using TensorRT+tkDNN
32 FPS — YOLOv4 (416x416 batch=1) on Jetson AGX Xavier — by using TensorRT+tkDNN

First, some useful links
You can read the detailed description of the features used in YOLOv4 in this article: https://medium.com/@jonathan_hui/yolov4-c9901eaa8e61
Full structure of YOLOv4: https://lutzroeder.github.io/netron/?url=https%3A%2F%2Fraw.githubusercontent.com%2FAlexeyAB%2Fdarknet%2Fmaster%2Fcfg%2Fyolov4.cfg
Step-by-step instructions for compiling and using YOLOv4 on the GPU in the Google-cloud using Jupyter Notebook — you just need to follow the link, click the “Copy to drive” button from the top-left corner, and then click the arrows in square brackets [ > ] in sequence — you will see all the commands which are executed, their results, and in Step 5 an image with detected objects:
How to compile and Detect in cloud for free:
- colab: https://colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- video: https://www.youtube.com/watch?v=mKAEGSxwOAY
How to compile and Train in cloud for free:
- colab: https://colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- video: https://youtu.be/mmj3nxGT2YQ
How to use Darknet on your computer:
- how to install Darknet YOLOv4: https://www.youtube.com/watch?v=5pYh1rFnNZs
- how to run Darknet YOLOv4: https://www.youtube.com/watch?v=sUxAVpzZ8hU
YOLOv4 Review CGMoon: https://neverabandon.tistory.com/22 (PDF: https://blog.kakaocdn.net/dn/bNOEgi/btqFkU7wjKW/cWh2LlkhXzKdm8B2EErzYK/YOLOv4_Review_CGMoon.pdf?attach=1&knm=tfile.pdf )
Neural networks comparison
Our YOLOv4 neural network and our own Darknet DL-framework (C/C++/CUDA) are better in FPS speed and AP50:95 and AP50 accuracy, on Microsoft COCO dataset, than the following DL-frameworks and neural networks: Google TensorFlow EfficientDet, FaceBook Detectron RetinaNet/MaskRCNN, PyTorch Yolov3-ASFF, and many others … YOLOv4 achieves 43.5% AP / 65.7% AP50 accuracy according to Microsoft COCO test at speed 62 FPS TitanV or 34 FPS RTX 2070. Unlike other modern detectors, YOLOv4 can be trained by anyone who uses the nVidia gaming graphics adapter with 8–16 GB VRAM. Now, not only large companies can train a neural network on dozens of GPUs / TPUs using large mini-batch sizes to achieve higher accuracy. We are giving back control over artificial intelligence to common users because YOLOv4 does not require large mini-batch, it is sufficient to use mini-batch=2–8.
YOLOV4 is optimal for real-time object detection tasks because the network lies on the Pareto optimality curve of the AP(accuracy) / FPS(speed) chart:
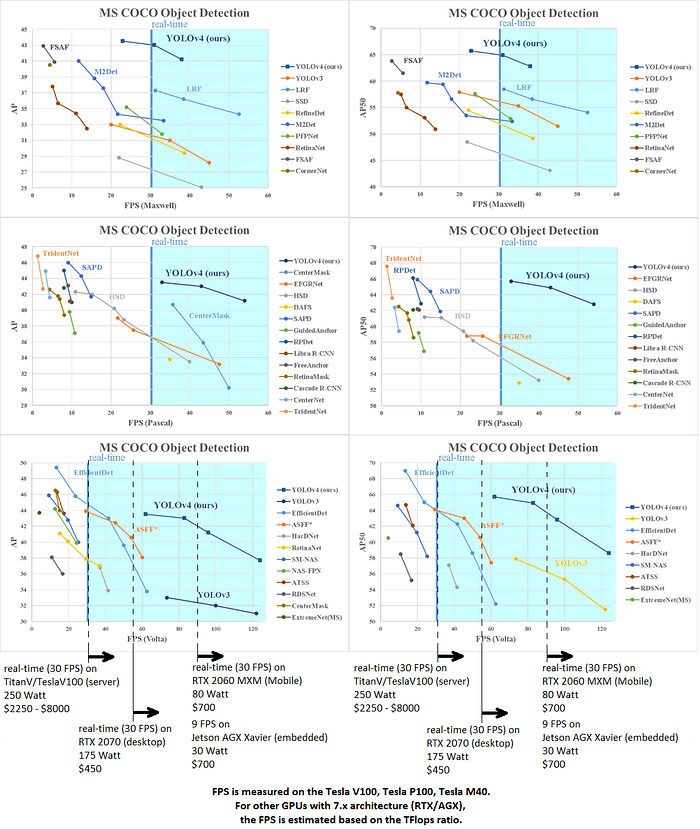
The most practical tasks have minimum necessary requirements for detectors — these are the minimum permissible accuracy and speed values. Usually, the minimum permissible speed value is from 30 FPS (frames per second) or greater for real-time systems.
As can be seen from the charts, in Real-time systems with FPS 30 or more:
- for YOLOv4–608 it is necessary to use RTX 2070, at $ 450 (34 FPS), with an accuracy of 43.5% AP / 65.7% AP50
- for EfficientDet-D2, it is necessary to use TitanV, at $ 2250 (42 FPS), with an accuracy of 43.0% AP / 62.3% AP50
- for EfficientDet-D0, it is necessary to use RTX 2070, at $ 450 (34 FPS), with an accuracy of 33.8% AP / 52.2% AP50
I.e. YOLOv4 requires 5 times less expensive equipment and yet is more accurate than EfficientDet-D2 (Google-TensorFlow). You can use EfficientDet-D0 (Google-TensorFlow) on cheap equipment, but then the accuracy will be 10% AP lower.
Besides, some industrial systems have restrictions on heat emission or the application of a passive cooling system — in this case, you cannot use TitanV even if it is affordable.
When using YOLOv4 (416x416) on GPU RTX 2080 Ti using TensorRT+tkDNN, we achieve the twice higher speed, and when using batch=4 the speed is even 3–4 times higher. For a fair comparison, we do not provide these results in the article on arxiv.org:

YOLOv4 (416x416) FP16 (Tensor Cores) batch=1 reaches 32 FPS on nVidia Jetson AGX Xavier computer when using TensorRT+tkDNN library: https://github.com/ceccocats/tkDNN
The OpenCV library that is compiled with CUDA/cuDNN gives a slightly lower speed: https://docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
Also YOLOv4-tiny model was released, with extremely high speed 370 FPS on GPU 1080ti, or 16 FPS on Jetson Nano (max_N, 416x416, batch=1, Darknet-framework). Up to 1000 FPS by using OpenCV / tkDNN-TensorRT: https://github.com/AlexeyAB/darknet/issues/6067

Sometimes the speed (FPS) of some neural networks is indicated when using a high batch size or when testing with specialized software (TensorRT), which optimizes the network and shows an increased FPS value. Comparison of some networks on TRT with other networks without TRT is not equitable. Also using a high batch size increases FPS, but also increases delay (rather than decreasing it) compared to batch = 1. If the network with batch = 1 shows 40 FPS, and the network with batch = 32 shows 60 FPS, then the delay will be 25 ms for batch = 1, and ~ 500 ms for batch = 32, because only ~ 2 batches (32 images apiece) will be processed per second. For this reason, using batch = 32 is not acceptable in many industrial systems. Therefore, we only show results with batch = 1 and without using TensorRT on comparison graphs.
Any process can be controlled either by people or computers. When a computer system operates with great delay due to low speed and makes too many mistakes, then we cannot entrust it full control over the process. In this case, the process shall be controlled by people, while the computer will only give tips. When the system works quickly and with high accuracy, such the system can manage the process independently, and people will only control its activities. Therefore, both accuracy and speed of the system are always important. If you think that 120 FPS for YOLOv4 416x416 is too much for your task, and it is better to use a slower and more accurate algorithm, then most likely that in real tasks you will use something weaker than Tesla V100 250 Watt ($8000), for example, RTX 2060/Jetson-Xavier 30–80 Watt. In this case, you will get 30 FPS for YOLOv4 416x416, while other neural networks will show 1–15 FPS or will not start at all.
Features of training various neural networks
You must train EfficientDet with mini-batch = 128 size on multiple Tesla V100 32GB GPUs, while YOLOv4 was trained on just one Tesla V100 32GB GPU with mini-batch = 8 = batch/subdivisions, and can be trained on a regular 8–16GB GPU-VRAM gaming graphics card.
The next problem is the difficulty of training a neural network to detect its own objects. No matter how long you train other networks on a single 1080 Ti GPU, you will not achieve the declared accuracy shown in the chart above. Most networks (EfficientDet, ASFF, …) need to be trained on 4–128 GPUs (with a larger mini-batch size using syncBN) and it is necessary to re-train anew for each network resolution. Without fulfilling both these conditions it is impossible to achieve the AP or AP50 accuracy claimed for them.
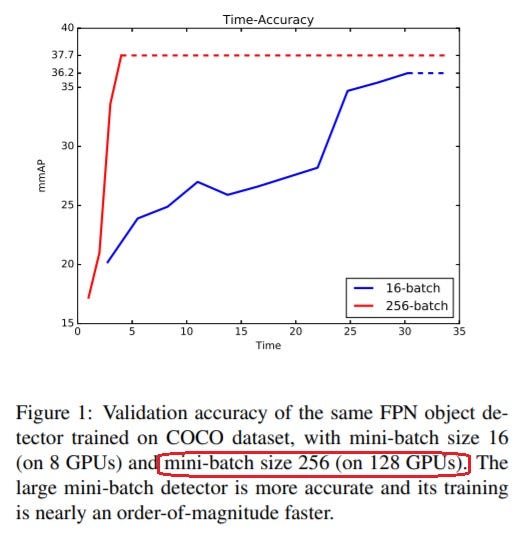
Yolo ASFF: https://arxiv.org/abs/1911.09516
Following [43], we introduce a bag of tricks in the training process, such as the mixup algorithm [12], the cosine [26] learning rate schedule, and the synchronized batch normalization technique [30].
EfficientDet: https://arxiv.org/abs/1911.09070
Synchronized batch normalization is added after every convolution with batch norm decay 0.99 and epsilon 1e-3.
Each model is trained 300 epochs with batch total size 128 on 32 TPUv3 cores.
https://cloud.google.com/tpu/docs/types-zones#europe
v3–32 TPU type (v3) — 32 TPU v3 cores — 512 GiB Total TPU memory
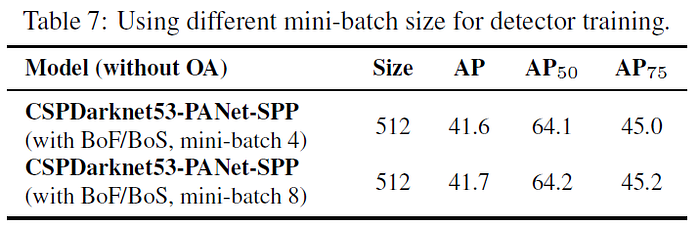
You need to use 512 GB of TPU/GPU-RAM to train the EfficientDet model with Synchronized batch normalization with batch=128, while YOLOv4 training requires only mini-batch=8 and 32 GB of GPU-RAM. Despite this, YOLOv4 is faster/more accurate than public networks, although it is trained only once at a resolution of 512x512 on 1 GPU (Tesla V100 32GB / 16GB). At the same time, using a smaller mini-batch size and GPU-VRAM does not lead to such a dramatic decrease in accuracy as in other neural networks:
So you can train artificial intelligence locally on your PC, instead of uploading dataset to the cloud. This protects your personal data and makes artificial intelligence training available to everyone.
It is enough to train our network once, at a network resolution 512x512, and then it can be used with different network resolutions in the range: [416x416–512x512–608x608]. Most other models need to be retrained specifically for each network resolution, and therefore such training needs a lot more time.
Features of measuring the accuracy of object detection algorithms
There can always be an image where one algorithm will work poorly, while another algorithm will work well and vice versa. Therefore, for testing detection algorithms a large set of ~20,000 images and 80 different types of objects (MSCOCO test-dev dataset) is used.
To prevent the algorithm from simply trying to remember the hash of each image and the coordinates on it (overfitting), the accuracy of object detection is always checked on images and tags that were not included in the training of the algorithm. This ensures that the algorithm can detect objects at images/videos that it has never seen.
So that no one can make an error in calculating accuracy, only test-dev images are publicly available, which you use for detection, while the results are sent to the CodaLab evaluation server, where the program itself compares the results with test annotations that are not available to anyone.
MSCOCO dataset includes 3 parts: http://cocodataset.org/#download
- Training set: 120,000 images and a json file with the coordinates of each object
- Validation set: 5,000 images and a json file with the coordinates of each object
- Test set: 41,000 jpg images without object coordinates (some of these images are used to determine accuracy in the following tasks: Object Detection, Instance Segmentation, Keypoints, …)
Features of the development of YOLOv4
When developing YOLOv4, we had to develop both the YOLOv4 neural network and the Darknet framework on C / C ++ / CUDA by myself. Because in Darknet there is no automatic differentiation and automatic execution of chain rules, then all the gradients have to be implemented manually in CUDA C++. On the other hand, we can depart from strict adherence to the chain-rule, change backpropagation and try very non-trivial things to increase learning stability and accuracy.
Additional conclusions when creating neural networks
· The best network for classifying objects is not always the best network to be used as a backbone for the network used for detecting objects
· Using weights trained with features that have increased accuracy in classification may negatively affect the accuracy of the detector (in some networks)
· Not all features stated in various studies improve the accuracy of the network
· Not all features are compatible with each other and some combinations of features often reduce the accuracy of the network when used together.
· It is not always the case that a network with lower BFLOPS will be faster, even if the BFLOPS is ten times lower
· Object detection networks require higher network resolution to detect multiple objects of different sizes and their exact location. This, in its turn, requires the higher receptive field to cover the increased network resolution, which means more layers with stride=2 and/or conv3x3, and larger weights (filters) size to remember more object details.
Using and training YOLOv4
Object detection using trained YOLOv4 models is built into the OpenCV-dnn library https://github.com/opencv/opencv/issues/17148 so you can use YOLOv4 directly from OpenCV without Darknet framework. The OpenCV library supports neural networks on CPU, GPU (nVidia GPU), and VPU (neurochip Intel Myriad X). See for more details: https://docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
OpenCV framework:
- Example in C++: https://github.com/opencv/opencv/blob/master/samples/dnn/object_detection.cpp
- Example in Python: https://github.com/opencv/opencv/blob/master/samples/dnn/object_detection.py
Darknet framework:
- Instructions for YOLOv4 use for object detection: https://github.com/AlexeyAB/darknet#how-to-use-on-the-command-line
- Instructions for training a neural network to detect its own objects: https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
- Instructions for training the CSPDarknet53 classifier on the ILSVRC2012 dataset (ImageNet): https://github.com/AlexeyAB/darknet/wiki/Train-Classifier-on-ImageNet-(ILSVRC2012)
- Instructions for training YOLOv4 on the MS COCO dataset: https://github.com/AlexeyAB/darknet/wiki/Train-Detector-on-MS-COCO-(trainvalno5k-2014) — dataset
tkDNN+TensorRT — Maximum speed of object detection using YOLOv4: TensorRT + tkDNN https://github.com/ceccocats/tkDNN
- 300 FPS — YOLOv4 (416x416 batch=4) on RTX 2080 Ti
- 32 FPS — YOLOv4 (416x416 batch=1) on Jetson AGX Xavier
Tencent-NCNN (C/C++/GLSL) — Maximum speed of object detection on Smartphones (iOS/Android) without any 3rd-party libraries or dependencies: https://github.com/Tencent/ncnn
The use of YOLOv4 can be expanded to detect 3D-Rotated-Bboxes or keypoints/facial landmarks, for example:
3D-Rotated-Bboxes: https://github.com/maudzung/Complex-YOLOv4-Pytorch

Keypoints/facial landmarks: https://github.com/ouyanghuiyu/darknet_face_with_landmark

